
2024-11-06 09:53:34.AIbase.
Une équipe chinoise publie le plus grand ensemble de données multimodales open source au monde, performance record pour un modèle à 2 milliards de paramètres

2024-11-06 09:29:51.AIbase.
L'équipe chinoise lance Infinity-MM, le plus grand ensemble de données multimodales au monde, et Aquila-VL-2B, un modèle d'IA miniature de pointe

2024-10-12 11:38:17.AIbase.
OpenAI publie MLE-bench : un ensemble de données d'évaluation pour les agents d'IA

2024-09-09 14:08:03.AIbase.
Getty Images lance un ensemble de données d'entraînement IA : 3750 photos haute résolution disponibles gratuitement

2024-08-31 10:41:54.AIbase.
L'organisation à l'origine de l'ensemble de données utilisé pour entraîner Stable Diffusion affirme avoir supprimé le CSAM

2024-07-26 09:26:21.AIbase.
VoxBlink2 : Un ensemble de données d'identification de locuteur audio-vidéo open source, fruit d'une collaboration entre l'Université de Wuhan et l'équipe d'intelligence artificielle Jiu Tian de China Mobile

2024-06-19 14:23:57.AIbase.
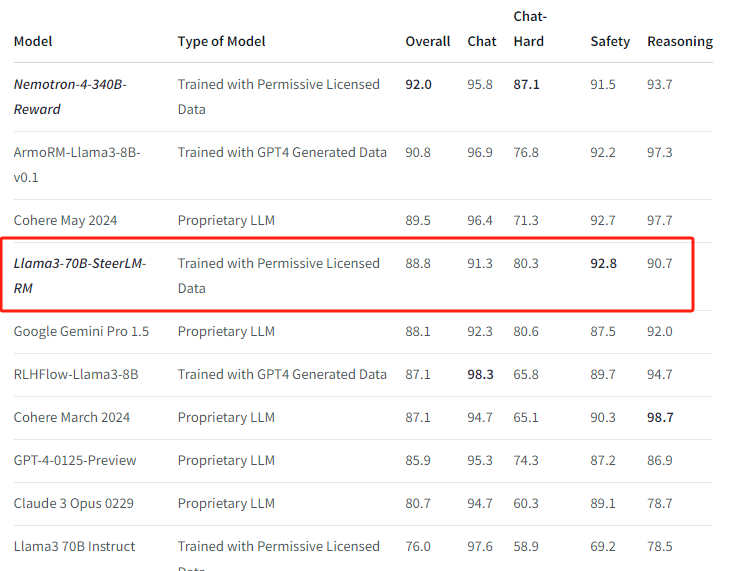
Nvidia lance un ensemble de données open source et un modèle à 7 milliards de paramètres : HelpSteer2 et Llama3-70B-SteerLM-RM
2023-12-25 14:12:47.AIbase.
L'Institut de Recherche sur l'Intelligence Artificielle (AIR) publie TACO, un ensemble de données d'entraînement pour la génération de code
2023-10-10 14:25:32.AIbase.
L'Académie chinoise des sciences lance OBIA, la première archive d'imagerie biomédicale ouverte de Chine
2023-09-18 11:23:15.AIbase.
Publication de MTP, le plus grand ensemble de données d'entraînement de modèles de vecteurs sémantiques chinois-anglais au monde, par l'Institut d'Intelligence Artificielle de Pékin (BAAI)
2023-08-24 10:46:12.AIbase.
AI2 publie l'ensemble de données open source Dolma pour les grands modèles de langage, contenant 3 billions de jetons
2023-08-21 10:21:44.AIbase.